Four Tips on How to Perform a Regression Analysis that Avoids Common Problems
This blog presents four tips that will help you avoid the more common mistakes of applied regression analysis that I identified in the research literature.
I’ll focus on applied regression analysis, which is used to make decisions rather than just determining the statistical significance of the predictors. Applied regression analysis emphasizes both being able to influence the outcome and the precision of the predictions.
Table of Contents
Tip 1: Use prior studies to determine which variables to include in the regression model
Before beginning the regression analysis, you should already have an idea of what the important variables are along with their relationships, coefficient signs, and effect magnitudes based on previous research. Unfortunately, recent trends have moved away from this approach thanks to large, readily available databases and automated procedures that build regression models.
If you want see the problem with data mining in action, simply create a worksheet in Minitab Statistical Software that has 101 columns, each of which contains 30 rows of random data, or use tdhis worksheet. Then, perform stepwise regression using one column as the response variable and all of the others as the potential predictor variables. This simulates dredging through a data set to see what sticks.
The results below are for the entirely random data. Each column in the output shows the model fit statistics for the first 5 steps of the stepwise procedure. For five predictors, we got an R-squared of 84.23% and an adjusted R-squared of 80.12%! The p-values (not shown) are all very low, often less than 0.01!
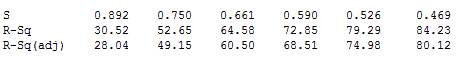
While stepwise regression and best subsets regression have their place in the early stages, you need more reason to include a predictor variable in a final regression model than just being able to reject the null hypothesis.
